Mahir on Call: Urdu-speaking AI front-desk assistant
Final Year Project · FAST-NUCES · 2026
The Problem
University admissions in Pakistan run on English-text-first portals. Applicants and parents from non-English-medium and rural backgrounds end up calling the front desk for things that should be self-serve - fee structures, scholarship eligibility, deadlines, hostel rules - and the front desk runs out of bandwidth during peak admissions windows. We wanted a voice agent that actually works for those callers.
That implies a few non-obvious requirements:
- Real Urdu and Roman-Urdu, not translated English. Generic LLMs handle dictionary Urdu, but stumble on code-switching ("admission ka kya process hai?") and Pakistani institutional vocabulary (semester freeze, "open merit").
- Grounded answers. A wrong fee number or a hallucinated scholarship deadline is operationally worse than no answer. Everything the agent says has to trace back to a source the university owns.
- Owned by non-engineers. Admissions policies change every cycle. If updating the system needs a developer in the loop, it rots in two months.
Our Approach (the pivot is the story)
V1 - Train a Roman-Urdu small language model from scratch
The first plan was to train a small Roman-Urdu language model ourselves and then fine-tune it on admissions Q&A. We learned the full architecture and everything needed to build a small language model from scratch from Sebastian Raschka's book Build a Large Language Model (From Scratch) ; following along, we built a GPT-2-style model, wrote the attention block, added positional encodings, set up the training loop, and started collecting Roman-Urdu text data. The code we wrote for the Roman-Urdu SLM lives in this GitHub repository.
Two walls hit us in close succession:
- Compute. Getting a usable Roman-Urdu SLM to a quality bar that beats a strong off-the-shelf model on bilingual responses needed orders of magnitude more GPU-hours than we had access to.
- Data. Quality Roman-Urdu institutional corpora don't exist at the scale this would have needed. Scraping wasn't going to bridge it.
The from-scratch work wasn't wasted - it gave the team a calibrated read on what GPT-4o-mini was actually doing internally, which paid off later when we were debugging retrieval failures and prompt-format edge cases.
V2 - RAG over a category-structured vector DB
The pivot: stop teaching a small model the institutional knowledge from scratch, and instead let a strong general model (GPT-4o-mini) handle language and reasoning while we ground its answers in a vector database that the admissions team owns.
Three design choices were load-bearing:
- Category structure, not flat similarity. Admissions policies, fee structures, scholarships, and academic guidelines each live in their own ChromaDB collection. The router decides which collection(s) to query per question - a fee question never retrieves an academic-guidelines snippet, and vice versa. Flat similarity was sending cross-category bleed into responses; category routing fixed that without changing the embedding model.
- Admin panel for non-engineers. The admissions staff are the source of truth, not us. The admin panel lets them upload PDFs, write structured FAQs, tag content with categories, and re-index - no developer involvement after rollout.
- Voice-first. Whisper for speech-to-text, TTS back to the caller. Most callers won't type, especially older parents, so the chat surface is secondary to the voice path.
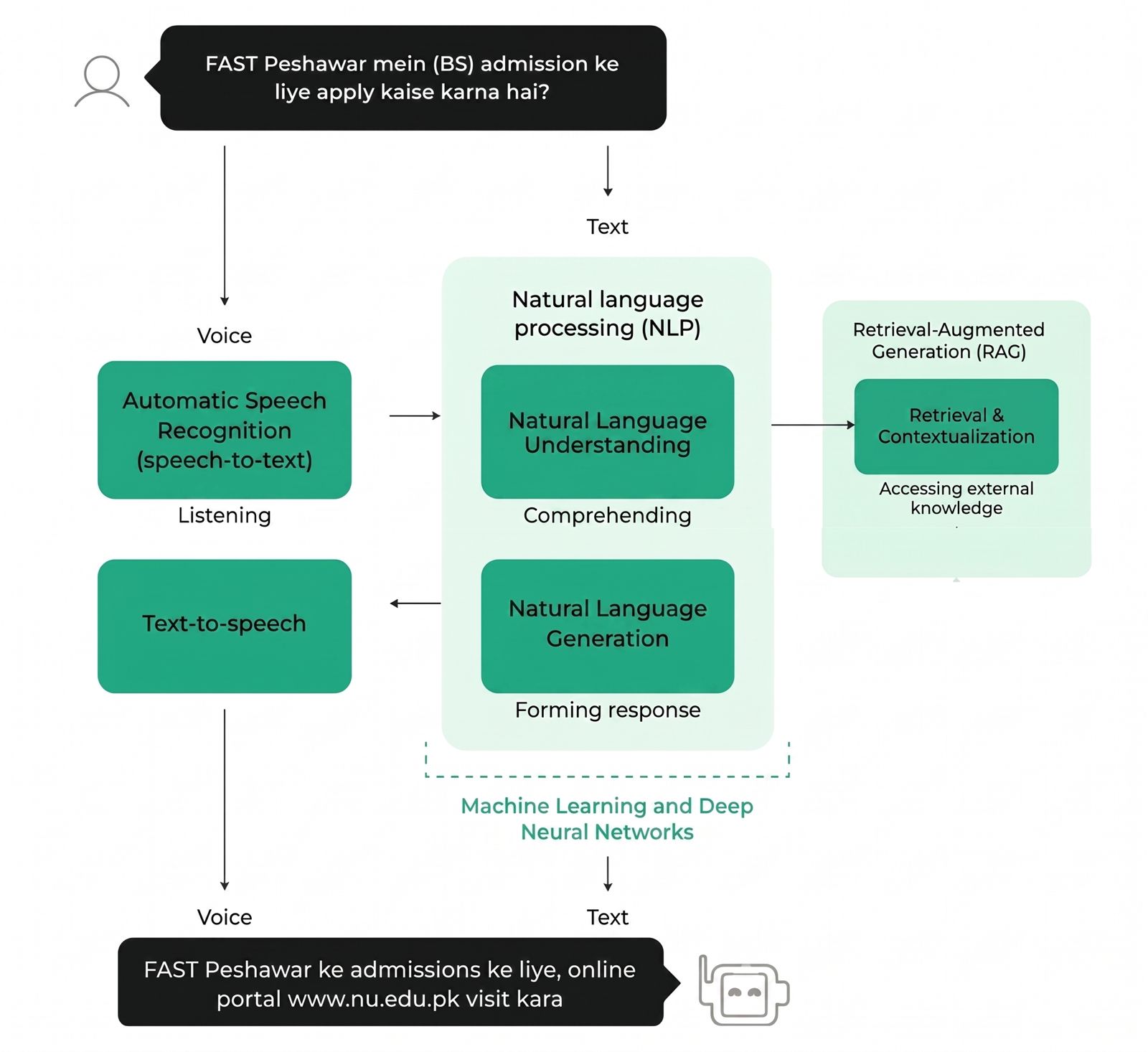
Figure 1 · High-level system architecture of Mahir on Call.
Use cases
Two actors: the User (any prospective student or parent on the university site) and the Moderator (authorised university staff with access to the knowledge base panel). The user's "Get Support" path includes a moderator follow-up via the admin panel.
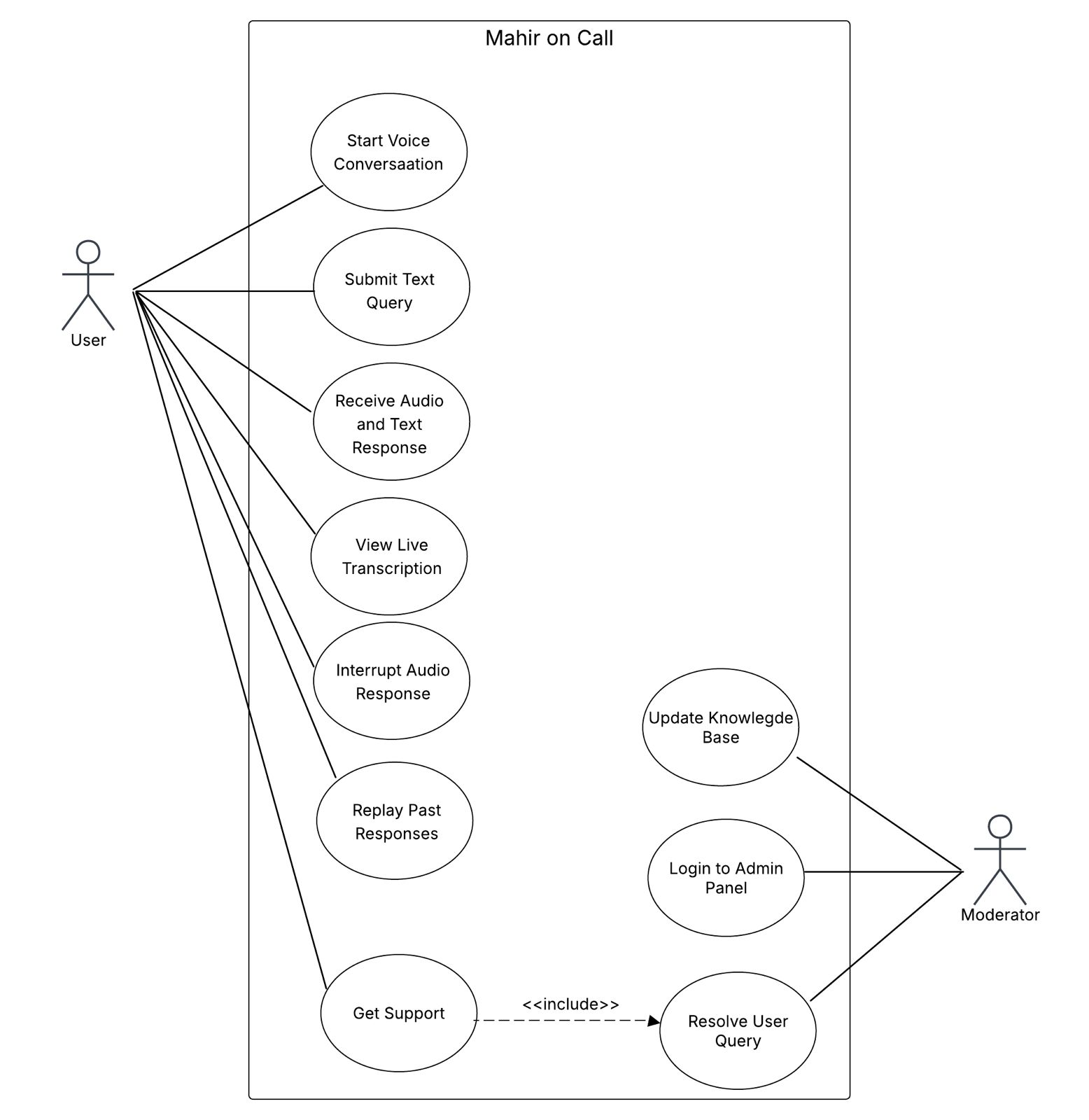
Figure 2 · Use case diagram.
Per-query activity flow
The activity diagram traces a single interaction from initial request to delivered response. The flow branches on input mode (call vs. text), converges through language detection, then runs the shared retrieval-generation path before branching again on output mode.
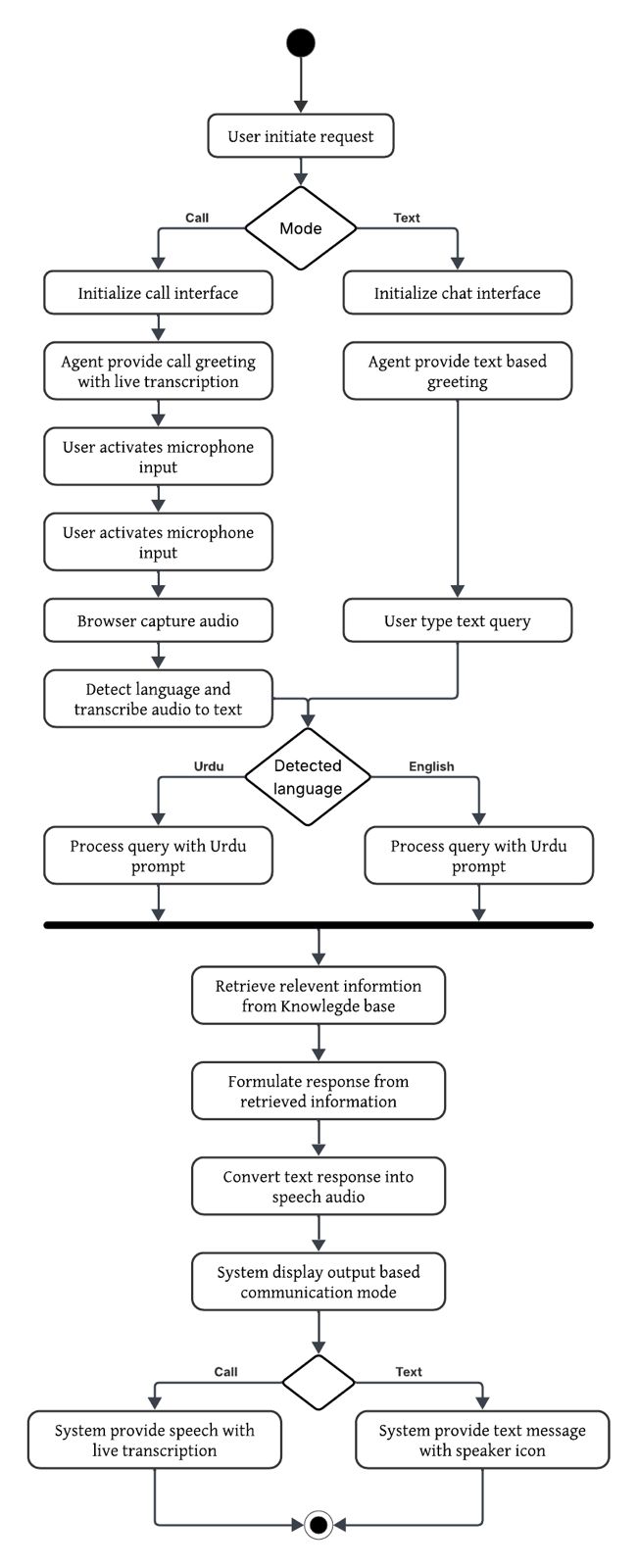
Figure 3 · Activity diagram for Mahir on Call.
Frontend state machine
The frontend is modelled as a five-state machine. At any moment the system occupies exactly one of Idle, Listening, Processing, Responding, or Error, no composite or undefined states are reachable, which makes the conversational rhythm predictable and the failure modes obvious.
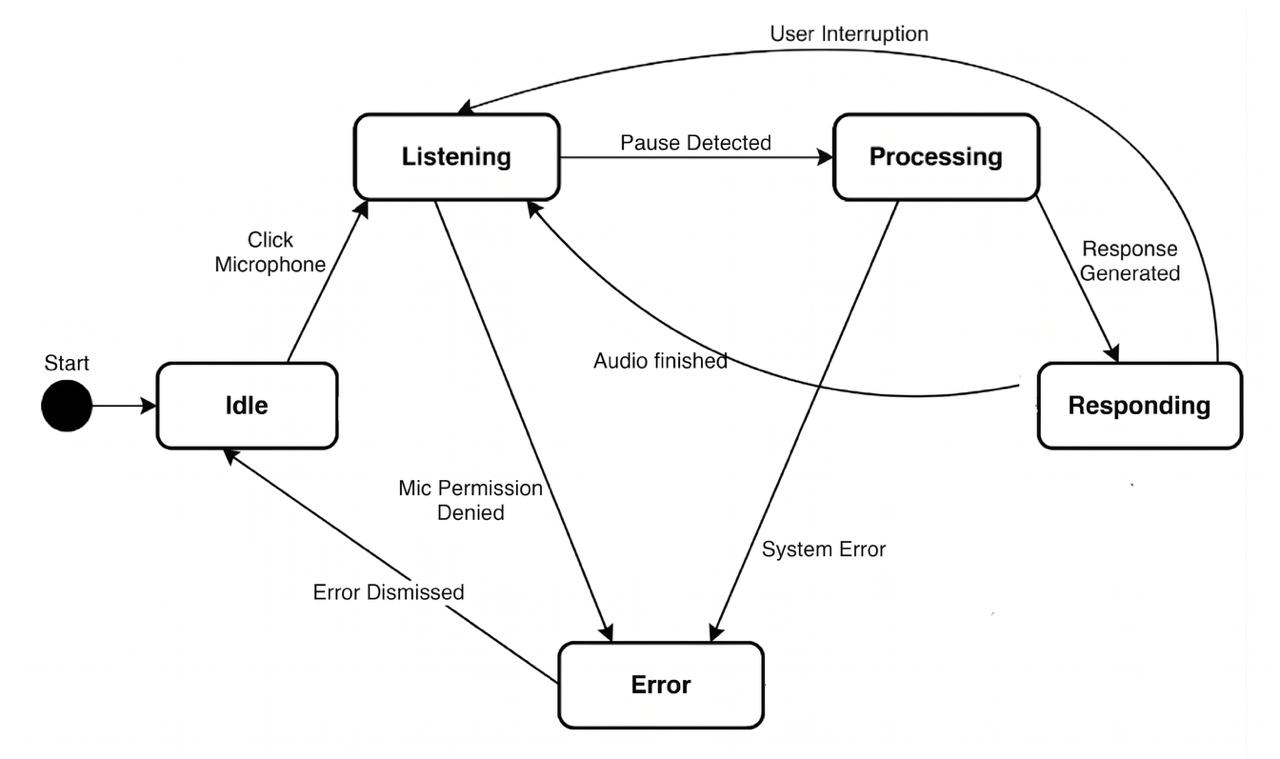
Figure 4 · State machine for the Mahir on Call frontend.
Takeaways
- Knowing when to stop training and start retrieving is an engineering instinct, not a coding skill. The SLM pivot was painful but right - the time we would have spent fighting compute and data scarcity bought us a better V2.
- Category structure beat retrieval-algorithm tweaking at this scale. A simple LLM-based router into named collections eliminated more answer-quality issues than any embedding model swap or rerank stage we tried.
- Admin tools are the difference between a demo and a maintainable system. The day the admissions staff updated a fee table without telling us, and the agent picked it up correctly on the next call, was when we knew the project was real.
- The from-scratch transformer work paid dividends downstream. Even after the pivot, debugging RAG behavior is much easier when you have a calibrated mental model of what's happening inside the model you're calling.